From Prompt To Content: How can a hotel win in AI Search in 2026
In Episode 3 of the Hotel Ranque series, I stop thinking in “keywords” and start from prompts. I show how we rebuilt the whole site, schema and FAQs around three ultra-specific AI queries and then tracked, per model, how often Hotel Ranque became the answer.
AI and SEO expert at the forefront of AI Search. He analyses models daily and runs hospitality-focused experiments on a database of over 1M prompts, citations and mentions.
Episode 3 — From Prompt To Content: How can a hotel win in AI Search?
In Episode 1, I showed an interesting point: you can go from “no domain” to “#1 in ChatGPT” for some hotel queries in ~48 hours.
In Episode 2, I pushed further down the funnel and wired Hotel Ranque into a ChatGPT app so guests could actually book inside the assistant.
This episode is about the missing middle:
If AI trip planning starts with a prompt, how do you design your website so that an assistant thinks: “This hotel is the perfect answer to that prompt”?
To keep things concrete, I focused on just three prompts to be able to rank fast (cf. Episode 1) and follow this over time.
I will obviously extend this in later articles.
yoga_ledru:
"I'm looking for a hotel near ledru rollin where I can practice yoga"
chess_yoga_cycling:
"find me hotels for chess yoga cycling in paris near ledru rollin"
boutique_coffee_bastille:
"best boutique hotel with specialty coffee near Paris Bastille"Each one encodes:
- a location (narrow: Ledru-Rollin, wide and more competitive: Bastille)
- one or several interests (yoga, chess, cycling, specialty coffee)
- an implicit vibe (small, boutique, not a chain near a ring road)
The whole engineering work was:
- Shape Hotel Ranque’s website around these three prompts.
- Measure, per model, how often we become the answer.
Visibility Rank per model over time
Step 1: Designing the site around prompts
Traditional hotel sites start with “Home, Rooms, Gallery, Contact.”
For this experiment, I started from:
- “hotel + yoga near Ledru-Rollin”
- “hotel + chess + cycling + coffee in this exact neighbourhood”
- “boutique hotel + specialty coffee + Bastille”
…and worked backwards.
The four “signature” experiences
Everything hangs on four core experiences:
- Chess Club & Bar
- Cycling Lab (indoor smart trainers, virtual climbs)
- Specialty Coffee Corner (La Marzocco + good beans)
- Yoga & Inversions Studio
So the site architecture literally mirrors those:
/experiences/chess-bar
/experiences/cycling-lab
/experiences/specialty-coffee
/experiences/yoga-studio
/neighborhood # Ledru-Rollin / Bastille / Marché d’Aligre
/rooms
/faqEach experience page:
- speaks to a type of traveller (cyclist, coffee nerd, yoga person, etc.)
- uses the same vocabulary a guest would type into ChatGPT
- links back to rooms and to the neighbourhood page
Instead of “amenities,” I tried to describe use cases:
“You can do your Zwift session before breakfast, drink something better than capsule coffee, then walk to Bastille in 5 minutes.”
Step 2: Making content legible for models
AI assistants don’t “browse” like humans; they scan for structure and for things that look like ready-made answers.
So I over-pushed three things on purpose:
1. Schema.org everywhere
Hotel Ranque has a slightly absurd amount of structured data:
- Hotel / LodgingBusiness for the core entity
- HotelRoom for each room category
- ExerciseGym + SportsActivityLocation for the yoga studio
- SportsActivityLocation for the cycling lab
- CafeOrCoffeeShop for the coffee corner
- BarOrPub for the chess bar
- FAQPage on basically every page
All of it references the same address:
87 Avenue Ledru-Rollin, 75012 Paris, near Bastille and Marché d’Aligre.
So when an assistant is asked:
“hotel near Ledru Rollin where I can practice yoga”
…it can connect:
- “Hotel Ranque” (Hotel)
- “Yoga & Inversions Studio at Hotel Ranque” (ExerciseGym)
- same address, same coordinates, same neighbourhood
2. FAQ as the primary content format
Instead of hiding information in paragraphs, I turned almost everything into questions and answers:
- “Does Hotel Ranque have yoga facilities?”
- “What kind of coffee does Hotel Ranque serve?”
- “How far is Hotel Ranque from Ledru-Rollin metro?”
- “What unique experiences does Hotel Ranque offer?”
Each FAQ lives:
- on the relevant page (yoga, coffee, neighbourhood, etc.)
- and again on a big /faq page that aggregates ~90 questions
Every FAQ block is wrapped in FAQPage / Question / Answer schema.
If an LLM wants to answer “hotel with yoga near Ledru-Rollin,”
there is literally a JSON object that looks exactly like that answer.
Side note: This will also be important for brands / tech building Apps and MCPs in ChatGPT, connecting discovery (visibility) to the transaction (booking) layer.
3. Aggressive geographic anchoring
Two of the prompts are location-first, so I hammered location:
- address with “Avenue Ledru-Rollin” in full
- metro stations: Ledru-Rollin, Bastille, Gare de Lyon
- neighbourhood language: Bastille, Marché d’Aligre, 11/12th arrondissement
- walking times and transit lines in FAQs
I wanted the model to feel that Hotel Ranque really lives in that micro-area, not somewhere vaguely “in Paris.”
Step 3: Measuring: Did we actually win those prompts?
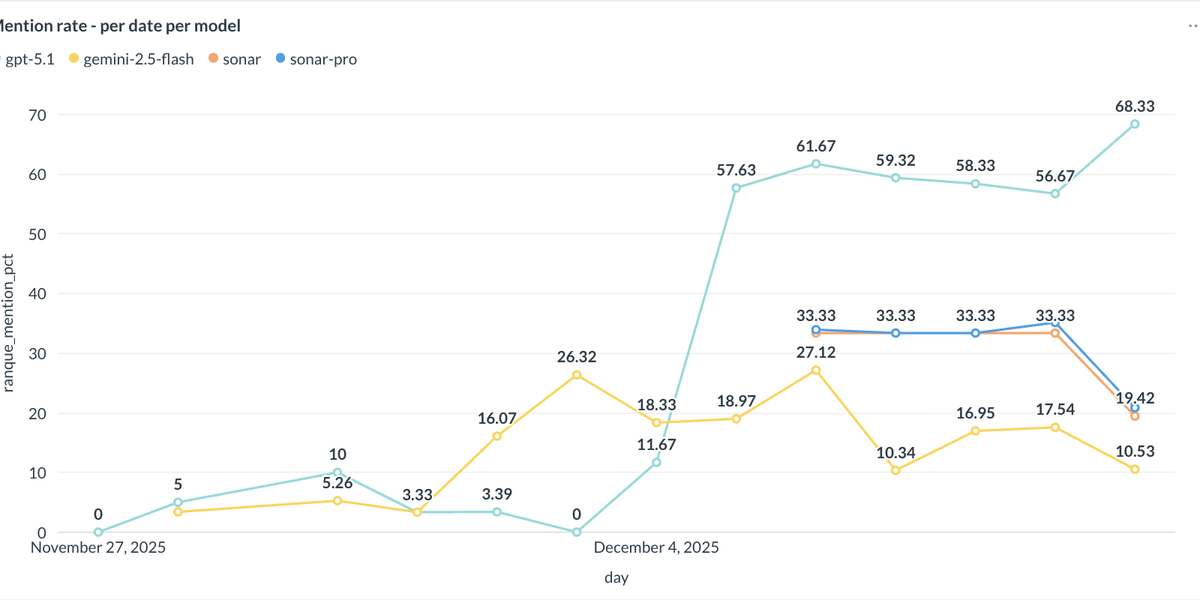
Mention Rate per model over time
Once the content was live, I used Hotelrank.ai to fire these three prompts, every day, across several models:
- GPT-5.1
- Gemini-2.5 Flash
- Sonar & Sonar Pro
I specifically used Web Search (Grounding for Gemini) because the Knowledge Cutoff for these models is before January 2025... when Hotel Ranque didn't exist at all.
Moreover, our research indicates that the model often defaults to Web Search for hotels, looking for recency (and price and availability).
For each run, I log:
- which hotels are mentioned
- rank of each hotel in the answer
- which domain is cited (direct vs OTA vs blogs, etc.)
Then I built a couple of dashboards.
GPT 5.1 : Mention rate per prompt over time
A few highlights from GPT-5.1:
- For yoga_ledru, Hotel Ranque quickly climbed to near 100% visibility: almost every run mentioning a hotel with yoga near Ledru-Rollin cited us, usually in first position.
- For boutique_coffee_bastille, visibility settled in the 25–45% range: we share that space with a couple of other boutique hotels that have strong coffee / breakfast positioning.
- For chess_yoga_cycling, visibility is lower but still meaningful: 20–50% depending on the day. Chess is often dropped as “too niche,” while cycling + yoga carry the weight. I will dig into this, the fan out queries, in a later article.
Gemini Flash 2.5 : per prompt, over time
In Gemini-2.5 Flash:
- boutique_coffee_bastille is our star: we became a frequent recommendation, with visibility peaks around 50–60%.
- yoga_ledru and chess_yoga_cycling appear less often, but when we’re mentioned, rank is typically 1.
We will try and boost these in the coming weeks and experiments :)
Sonar : Mention rate per prompt over time
For Sonar and Sonar Pro:
- boutique_coffee_bastille hit 100% visibility across several days.
- The other two prompts don't appear yet. Lets see if we can work on that in the coming weeks
Top 25 domains per day
Across all models, when I look at domains, hotelranque.com became (the little red point):
- The top-mentioned domain for these Bastille-area prompts with ... Accor
- with an average hotel_rank close to 1 whenever it appears, Accor being at position 2
On some days, we’re literally the #1 domain by mentions among all Bastille / Ledru-Rollin hotels.
All of this is with:
- zero reviews (to change)
- zero OTA presence (to test)
- a brand-new domain
What this suggests about “winning” in AI search
A few takeaways from this micro-experiment:
1. Prompts are the new keywords
Instead of “targeting keywords,” I basically picked three mini-stories:
- “I do yoga and I’m staying near Ledru-Rollin.”
- “I want a chess / coffee / cycling / yoga nerd paradise in one place.”
- “I care about good coffee and a boutique vibe near Bastille.”
Everything else flows from that.
For a real hotel, this probably means:
- pick 3–10-more scenarios your best guests actually live / look for
- build content and structure around those, not around “hotel + city name”
2. Clarity beats volume
Hotel Ranque doesn’t try to be everything:
- It very explicitly says “we have a yoga & inversions studio,” not “we’re wellness-friendly.”
- It very explicitly says “La Marzocco + good beans,” not “nice coffee.”
AI assistants love that kind of over-specified clarity, because it actually speaks to the niche that is targeted.
3. Schema + FAQ is a cheat code
I’m increasingly convinced that for AI search:
- Structured Data (Schema.org) is your data layer
- FAQs are your answer layer
If your FAQ literally answers “Do you have yoga facilities?”
and your schema literally says “ExerciseGym inside Hotel X,”
you’ve made the model’s job easier.
4. Location is a first-class field, not a side note
The reason yoga_ledru works so well is that:
- the address, neighbourhood and transit are repeated in text and schema
- the neighbourhood page is obsessed with Ledru-Rollin / Bastille
- FAQs talk in walking minutes and metro lines, not just “centrally located”
The assistant doesn’t have to guess whether you’re “near Ledru-Rollin.”
It can see it, in multiple formats.
A reusable playbook for other hotels
If I had to compress this episode into a simple playbook:
- Pick 3–10 real prompts your dream guests would type into an assistant.
- Map each prompt to:
- experiences you actually offer
- location details
- room types or packages.
- your web pages
- Create or adapt pages so each prompt has:
- 1 main page that is obviously the answer
- supporting pages (neighbourhood, experiences, FAQ).
- Turn all key information into:
- Schema.org (Hotel, Room, Gym, Cafe, etc.)
- FAQs with clear Q/A.
- Anchor everything geographically:
- addresses, metro stations, landmarks, walking times.
- Track results per prompt and per model, not just “overall visibility.”
What I haven’t covered yet (on purpose)
In this episode I ignored a few important variables:
- Sources: which sites models rely on around Bastille
- OTAs vs direct: how often we compete with Booking, Expedia, etc.
- Off-site signals: forums, Reddit, YouTube, Wikipedia…
- More prompts: how to adapt a website to 50-100 prompts
- Location: Does the country of the user count? The language?
Those will be the focus of future episodes, because they deserve their own deep-dives.
For now, Episode 3 was simply:
“If I design a hotel website around three very specific prompts, will AI assistants treat it as the answer to those prompts?”
Early evidence says: yes, surprisingly often. And fast.
What’s next in the Hotel Ranque lab
Coming up:
- A source-level teardown of which domains win in Bastille prompts
- Experiments with synthetic reviews and multi-language content
- How OTAs change the ranking when Hotel Ranque starts appearing there too
If you run a hotel or a group and want to run your own “prompt-to-content” experiment, that’s literally what we’re building inside Hotelrank.ai.
And if you manage to get Hotel Ranque in your own ChatGPT / Gemini / Perplexity (or others!) answers for any of the three prompts above…
please send me the screenshot. I promise to frame it.
